Tijdens de SWIB18 conferentie in Bonn presenteren we de resultaten van AdamLink. In ons project hebben we metadata uit verschillende erfgoedcollecties gecombineerd, zo bruikbaar mogelijk gemaakt en vervolgens aangeboden om door zoveel mogelijk mensen te gebruiken. Om onze dataset zo bruikbaar mogelijk te maken hebben we transformaties uitgevoerd. Zo vertalen we bijvoorbeeld allerlei veldnamen naar een aantal gemeenschappelijke properties, standaardiseren het gebruik van uri’s en hebben enkele eigen data toegevoegd. In ons stuk ‘Transformations for aggregated linked open data‘ en onze presentatie geven we een overzicht van de soorten transformaties die we denken dat noodzakelijk zijn als je data bij elkaar brengt om eenvoudig doorzoekbaar te kunnen aanbieden.
Afgelopen jaar heb ik verschillende presentaties mogen houden over het project. De vraag van een erfgoedinstelling was daarbij vaak: “Ik wil ook mijn data op deze manier beschikbaar stellen! Maar waar moet ik beginnen!?”.
Om een antwoord te geven op die vraag heb ik negen activiteiten op een rijtje gezet, gecategoriseerd in drie groepen. Ze komen terug in deze presentatie die ik voor het eerst gaf voor de leden van AdamNet in april 2018. In deze blog leg ik ze kort uit.
Voordat ik dat doe nog het volgende. Als je één van de activiteiten doet, is dat al beter dan helemaal niets. Vaak is het ook zo dat iets half kunt doen, bijvoorbeeld voor maar een deel van je collectie. Zo zijn we natuurlijk niet opgevoed. We willen het graag helemaal goed doen, maar bij het beschrijven van erfgoed zijn we nooit klaar. Er zijn altijd aanvullingen en verbeteringen te verzinnen. Dat geldt ook voor het verbeteren van je metadata om deze geschikt te maken voor publicatie als Linked Open Data (LOD). Enthousiast? Google de termen die je niet begrijpt: er is allerlei uitleg beschikbaar.
Leg rechten vast. We kunnen alleen data gebruiken waarvan duidelijk is dat er voor het gebruik geen juridische belemmeringen zijn (denk aan auteursrecht, openbaarheidsbeperkingen of privacywetgeving). Leg daarom bij objecten vast welke rechten er gelden. Als je het niet van alle objecten weet: ook goed, dan beperken we de publicatie straks tot de objecten waarvan we zeker weten dat het mag.
Introduceer URI’s. Elk object moet op het internet zijn te identificeren door een uniek webadres, dat bovendien voor altijd zal blijven werken. De uitspraken over het object (“deze ets is gemaakt door Rembrandt”) zijn aan deze zogenaamde uniform resource identifier (URI) te relateren. Een Persistent Identifier (PID) kan meestal als URI worden gebruikt.
Link de data. Je beschrijft een object door daarover uitspraken te doen: bv. “deze ets is gemaakt door Rembrandt”. In plaats van de tekst “Rembrandt” te linken, kun je beter Rembrandt kiezen uit een lijst van standaardnamen. Deze standaardnamen kunnen net als de objecten worden geidentificeerd met een URI. Dit geldt behalve voor personen ook voor bijvoorbeeld plaatsnamen en objectsoorten.
Zet de dataset online. Volgende stap hoeft niet moeilijk te zijn. Sla je data uit je database op in een bestand en zet dit bestand op je website. Iemand die op je website op het bestand klikt kan deze dan downloaden en gebruiken. Natuurlijk is het ene bestandsformaat handiger dan het andere, maar elk formaat is beter dan niets online zetten.
Zet de dataset online in RDF-formaat. Als je URI’s beschikbaar hebt en je data hebt gelinkt, kun je er voor kiezen om de data aan te bieden in een vorm van Resource Description Framework (RDF). Elke uitspraak over je object (bv. “Deze ets is gemaakt door Rembrandt”) is dan vertaald naar “triples”. Nu heb je Linked Open Data gepubliceerd!
De moeder van Rembrandt
Publiceer de data per object. Soms wil een gebruiker niet een volledige dataset met al je objecten en wil hij alleen iets weten over die ene ets. In dat geval moet je het in de website mogelijk maken om alleen die data te leveren via de URI van dat ene object. Er is dan sprake van een resolvable URI.
Bied een synchronisatie-mechanisme. Een gebruiker die je data regelmatig downloadt, wil na de eerste keer misschien alleen maar alle wijzigingen weten. Een synchronisatie-protocol zoals OAI-PMH of Resource Sync maakt dit mogelijk.
Bied een API. Een Application Programming Interface maakt het mogelijk dat een gebruiker een deel van de data opvraagt. Een API levert meestal data aan in JSON-formaat.
Bied een SPARQL-endpoint. Op een SPARQL-endpoint kan een gebruiker vragen aan de data stellen op alle manieren die hij of zij kan bedenken. Het is speciaal bedoeld voor Linked Open Data.
De laatste vier paragrafen zijn heel technisch. Dit is niet de plaats om daar verder op in te gaan. Laat je daar vooral niet door afschrikken. Het verbeteren van de data is een belangrijke stap in het beschikbaar maken van LOD en is belangrijker dan de realisatie van de techniek. En met data verbeteren kan iedereen beginnen. Actie!
Amsterdammers en GVB, gefeliciteerd met de Noord/Zuidlijn!
De Amsterdamse cultureel erfgoedinstellingen (AdamNet) bieden jullie daarom graag bij de opening van het nieuwe traject de erfgoedsite adamlink.nl/nzlijn aan.
Reis op de site per metrostation door het Amsterdamse cultureel erfgoed. Bekijk foto’s, tekeningen, kaarten, boeken uit het (recente) verleden waar je nu ongezien onderdoor rijdt. Ga zelf op onderzoek in onze collecties, of stap uit en breng een bezoek aan jouw eigen straat.
De culturele erfgoeddata ontsluiten we binnen het project AdamLink als Linked Open Data (LOD). Met deze techniek is het mogelijk om nieuwe verbanden te leggen tussen verschillende databronnen. Perfect voor onderzoeken, werkstukken of om op reis te gaan door de enorme rijkdom van het cultureel Amsterdams erfgoed.
Reis door de Tijd is ontwikkeld door AdamNet in samenwerking met NoProtocol. Het zoeken in de straten van Amsterdam is ontwikkeld door studenten van de HvA.
AdamNet is een netwerk van Amsterdamse bibliotheken. Doel is samenwerken in het beschikbaar stellen van informatie over collecties en activiteiten. In het project werkten samen: de Openbare Bibliotheek Amsterdam, de Bibliotheek UvA/HvA, de universiteitsbibliotheek VU, het Internationaal Instituut voor Sociale Geschiedenis, het Amsterdam Museum en het Stadsarchief Amsterdam. Deze productie werd financieel mogelijk gemaakt door Stichting Pica.
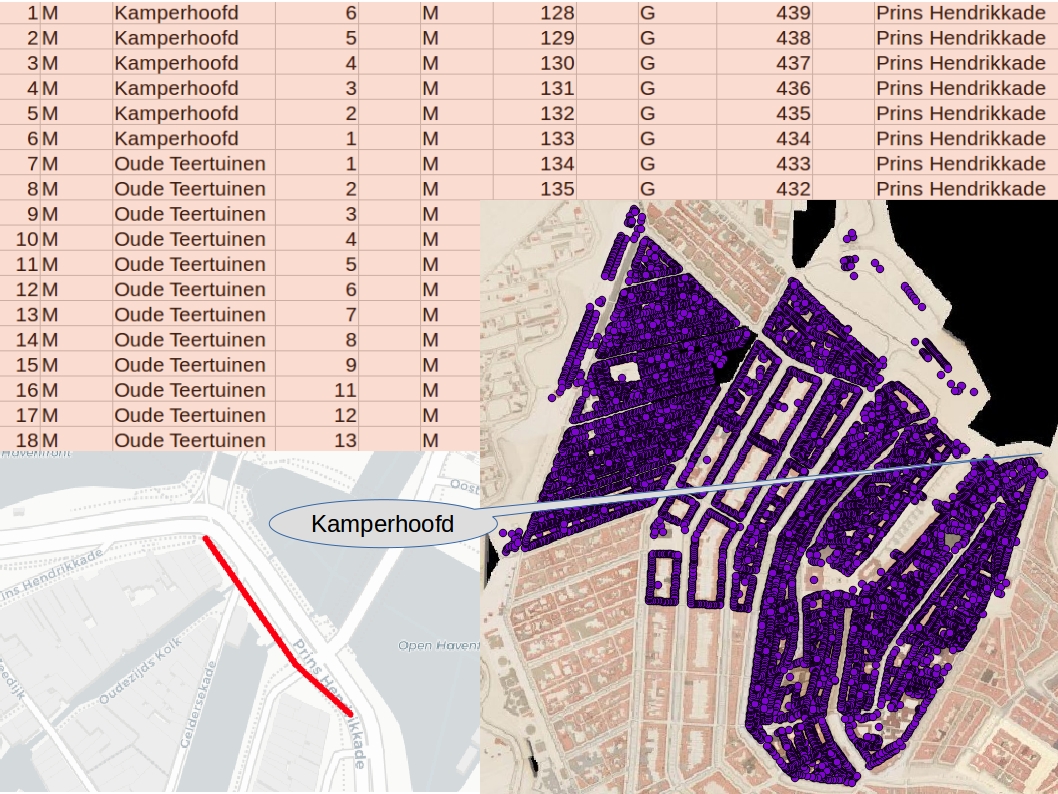
In Adamlink hebben we veel voorwerpen kunnen verbinden aan een straat, persoon of gebouw. Veel van de voorwerpen in de erfgoedcollecties zijn echter nog gedetailleerder ontsloten en hebben ook een adres in de beschrijving. Om bijvoorbeeld foto’s of prenten nog preciezer op een kaart te kunnen lokaliseren hebben we – net als bij de straten – een lijst van bestaande en niet meer bestaande adressen nodig. En de koppeling daartussen: het pand dat vroeger Jodenbreestraat 1 heette is niet hetzelfde pand dat nu Jodenbreestraat 1 heet.
In een project van CLARIAH en Amsterdam Time Machine werken we samen met HisGIS aan de Fryske Akademy in Leeuwarden om deze lijst van adressen te maken. Daar hebben ze namelijk veel ervaring opgedaan met het reconstrueren van adressen in steden. Ze gaan daarbij uit van de concordans die door het Stadsarchief beschikbaar wordt en verbeteren deze op basis van ondermeer de kadasterkaart (1832) en de kaart van Loman (1876). Naast de veranderingen in adressen, leggen ze ook de plaats op de kaart vast.
Behalve in de metadata over erfgoed zitten adressen ook in veel oude registraties, bijvoorbeeld de kiezerslijsten of de ledenadministratie van de diamantbewerkersbond (ANDB). Zodra dit soort registraties worden ingevoerd, kunnen ze snel en eenvoudig op een kaart worden weergegeven.
De Fryske Akademy heeft de ingewikkelde delen van de stad (het centrum en de Jordaan) al verwerkt. Zodra het af is, gaan we de erfgoedcollecties koppelen. We kunnen bijna niet wachten…
De eerste resultaten van de lijst van oude Amsterdamse adressen, gemaakt aan de Fryske Akademy.
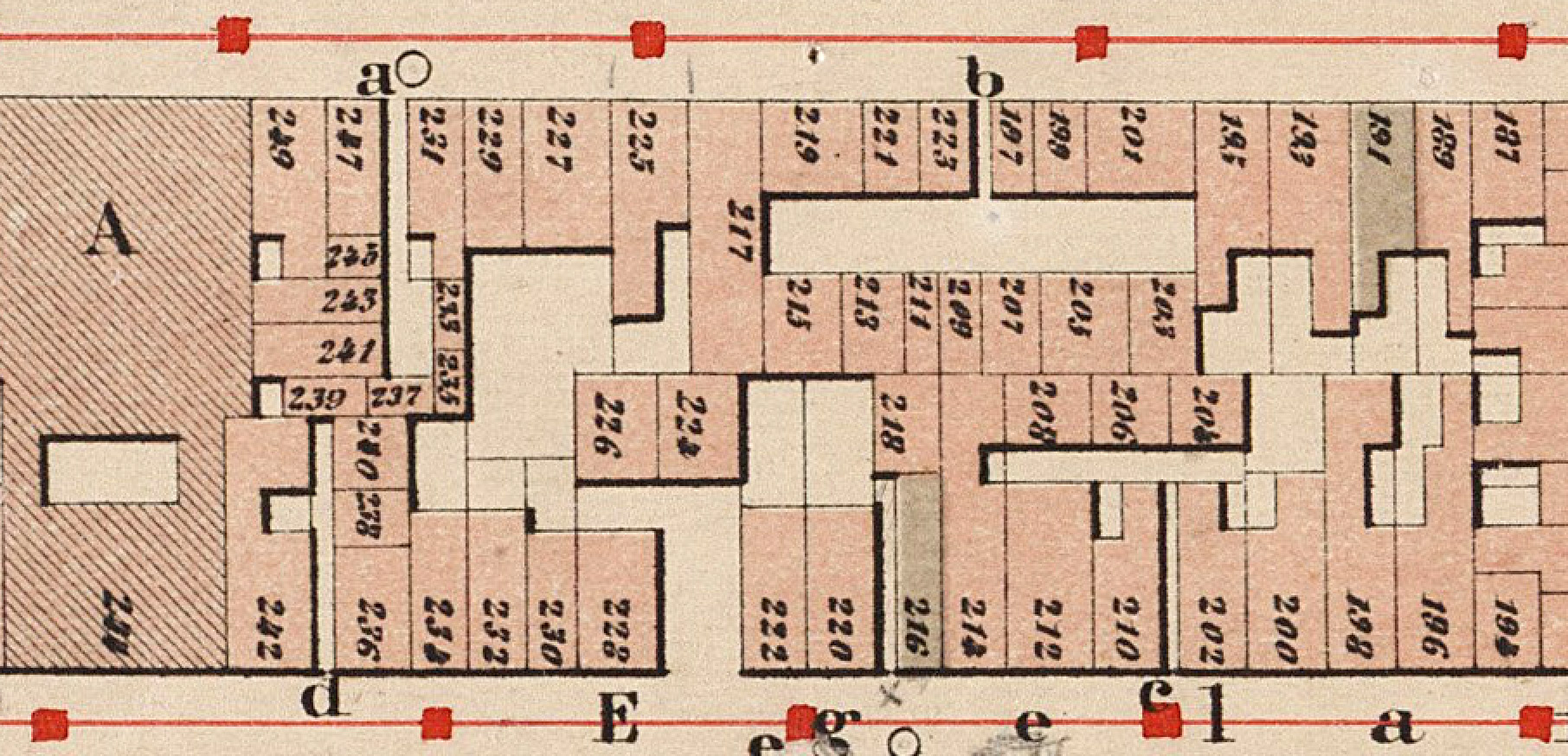
De Jordaan telde vroeger honderden gangen en hofjes. Het aantal woningen dat aan die gangen lag is natuurlijk nog veel groter. Die gangen zijn nu, tenminste voor zover ze op de 19e-eeuwse buurtatlaskaarten van naam waren voorzien, opgenomen in het Adamlink stratenregister.
De geometrieën zoals die nu in het stratenregister te vinden zijn
Je komt soms fraaie namen tegen: Moddermansgang, Stille Willemsgang, Prinsenliefhebbersgang. En mijn persoonlijke favoriet: Drie Hoedjesgang. Maar als je alle namen in alfabetische volgorde bekijkt valt juist het gebrek aan originaliteit op dat de Jordanezen vaak parten speelde. In de toptien van meestvoorkomende namen staan maar liefst 46 gangen!
Kuipersgang
9
Gruttersgang
6
Pijpenbrandersgang
5
Bakkersgang
5
Slagersgang
4
Sleepersgang
4
Smidsgang
4
Slagtersgang
3
Klokkengang
3
Fortuinengang
3
Een beter argument voor het het gebruik van unieke identifiers (ha, URIs, hoor ik u al mompelen) is natuurlijk niet te vinden.
Eén van de twee Kuipersgangen aan de Egelantierstraat, aangegeven met ‘d’.
Op de Hackalod begin dit jaar kreeg u al een proeve van een geografische ontsluiting van Amsterdamse kaartmateriaal – op een kaart kon u een punt aanwijzen om historische kaarten op te halen die dat punt bevatten.
Inmiddels is er een tweede prototype, waarop daarnaast ook op andere parameters gezocht kan worden. Tijd bijvoorbeeld, of maker, of (deel-)collectie. Daarmee is het mogelijk snel en precies 19e-eeuwse buurtkaarten van een bepaalde buurt op te vragen, of een 1:1000 kaart uit de Publieke Werken reeks van 1943.
Dit smaakt duidelijk naar meer. Binnen het huidige AdamNet project, dat tot het einde van de zomer loopt, is dat niet meer in te passen. Maar er wordt al voorzichtig aan een Cartografische Collectie Amsterdam gedacht!
Op Adamlink vind je naast overzichten van Amsterdamse gebouwen en straten ook een personenlijst. Hoe ziet die lijst eruit, wie mag er op, wie moet er op en wat beogen we ermee?
Verbindingspunten
Persoonsnamen zijn ondingen. Johannes Vermeer kan net zo goed als Johannes van der Meer te boek staan, of als Jan, of als Johannes Reyniersz., of als Jan Vermeer van Delft. Omgekeerd is Jurriaan Andriessen een 20ste-eeuwse componist, maar ook een 18e-eeuwse schilder.
De personen, of liever gezegd de persoonsconcepten op de lijst fungeren als verbindingspunten. Vermeer staat er op als één concept met al z’n naamvarianten en de twee Andriessens kunnen er prima naast elkaar bestaan. Elke Andriessen krijgt daarbij z’n eigen adamlink URI. Als zowel in de Stadsarchief data als in de Rijksmuseum data die URI gebruikt wordt om naar het concept van de 18e-eeuwse Andriessen te verwijzen, dan kunnen we al zijn werk probleemloos uit de verschillende collecties halen, zonder dat die componist er opeens tussen zit.
Jurriaan Andriessen (links) en Jurriaan Andriessen (rechts)
Hub
Er worden via zo’n persoonsconcept niet alleen verbindingen tussen verschillende collecties gelegd. Het concept legt ook verbindingen naar dezelfde persoon in, onder andere, Wikidata, Ecartico, RKDartists, VIAF en het Biografisch Portaal. Sommige instellingen hebben verwijzingen naar dergelijke sets ook al opgenomen in hun metadata, wat zekerheid geeft bij het identificeren van personen.
Als toegift bevatten die sets vaak veel meer informatie over zo’n persoon – geboorteplaats, beroep, van wanneer tot wanneer een bepaald ambt bekleed werd, religie, een lidmaatschap van Arti et Amicitiae, enzovoort.
Dankzij die verbindingen kunnen we straks alle afbeeldingen van protestantse kerken door katholieke kunstenaars ophalen, en omgekeerd – misschien kunnen we daarmee iets zeggen over religieuze ruimdenkendheid (of over principes die wijken voor geld).
Of met één query alle portretten van leden van Arti et Amicitiae tonen. Of portretten van mensen met een bepaald beroep, zoals we in deze ‘sample app’ al lieten zien.
Koppelingen leggen
Die koppelingen moeten natuurlijk wel eerst gelegd worden. Hoe gaat dat in de praktijk? Zoals gezegd is koppelen op naam alleen onbetrouwbaar – het IISG heeft bij wijze van test op naam koppelingen met VIAF gelegd, en dat bleek in 75-80% van de gevallen goed te gaan. Met andere woorden, 1 op de 4 à 5 koppelingen is fout.
Gelukkig hebben we zo nu en dan iets meer aanknopingspunten. Soms zijn behalve de naam ook geboorte- en sterfdata opgenomen. Soms hanteren musea nauwgezet de schrijfwijze die het RKD ook gebruikt. Het Amsterdam Museum heeft bij personen al duizenden URIs opgenomen, meest RKDartists en Ecartico. Wikidata heeft weer links gelegd naar diezelfde RKDartists, dus in veel gevallen is het ophalen van Wikidata URIs dan vrij eenvoudig.
Wikidata legt links naar nog veel meer externe identifiers, en samen met alle andere informatie die daar al te vinden is, maakt dat Wikidata onze favoriet.
Waar die aanknopingspunten ontbreken is het handwerk niet geschuwd. Als je als naam alleen ‘Cor Witschge’ hebt, maar op de afbeelding staat Pipo de Clown, dan is een link naar Wikidata snel met zekerheid te leggen. We hebben daarbij natuurlijk wel prioriteiten gelegd: personen die het vaakst geportretteerd zijn of het meeste werk hebben gemaakt staan bovenaan de todo-lijst.
Wat als het niet lukt?
Het juist koppelen van personen lukt vaker niet dan wel. Veel collecties hebben niet meer dan een naam opgeslagen (soms is in die naamstring een aanwijzing verwerkt, bijvoorbeeld een beroep of geboorte- en sterfjaren tussen haakjes achter de naam zelf, dat moet je er dan weer uit zien te halen). In die gevallen namen we als naam alleen de string op en dat ziet er zo uit:
Carmiggelt zal vast een idee gehad hebben van wat een ‘echte Amsterdammer’ was. Binnen het AdamNet team hebben we het er ook wel eens over. Met Amsterdam als geboorte- of sterfplaats krijg je natuurlijk punten, maar een hoop mensen die van belang zijn geweest voor de Amsterdamse geschiedenis zouden zo buiten de boot vallen. Het RKD houdt bij welke mensen werkzaam zijn geweest in Amsterdam, maar beperkt zich tot kunstenaars.
Misschien kan je stellen dat mensen die als geportretteerde voorkomen in ‘echte Amsterdamse collecties’ zoals die van het Stadsarchief en Amsterdam Museum ‘echte Amsterdammers’, of toch in elk geval ‘van belang voor de Amsterdamse geschiedenis’ zijn.
Dat we ons überhaupt met dit soort vragen bezig houden is niet Amsterdams-municipalistisch gedreven, zeg ik er voor de zekerheid maar bij.
De reden om tot zo’n lijst te willen komen is dat we zo makkelijker data kunnen samenbrengen die de Amsterdamse geschiedenis betreffen. Dat is immers het thema waar Adamlink zich op richt. Van (inter)nationale collecties, zoals die van het IISG of het Rijksmuseum, nemen we het vaak alleen het Amsterdamse deel op. We hebben niks tegen een portret van Marx, Engels of Lenin, en al evenmin tegen Italiaanse landschappen, maar het is niet onze taak dergelijke objecten beter te metadateren.
Met geografische concepten gaat dat makkelijker. Het Rijksmuseum heeft bijvoorbeeld een geografische thesaurus, zodat we alles dat ‘Amsterdam’ of onderliggende concepten als onderwerp heeft kunnen binnenhalen. Grote kans dat de personen die als maker of als onderwerp van die objecten genoemd worden een relatie met Amsterdam hebben – die nemen we dus ook weer op.
Fabiola, in Duitsland geboren, in België opgegroeid, maar toch een echte Amsterdammer.
In de week van 5 tot 9 maart bivakkeren studenten van de HvA-opleiding Communication and Multimedia Design op de MaakZone van de OBA. Zij prototypen op Linked Open Data van AdamLink.
De 35 studenten ontwikkelen toepassingen op Linked Open Data en zijn de hele week in de Maakzone bezig met het ontwikkelen van prototypes op het Adamlinkproject (https://www.oba.nl/over-ons/partners/adamlink/HvAlab.html). Ook presenteren zij 35 toepassingen op basis van de data van de Amsterdamse erfgoedinstellingen.
Bijvoorbeeld: bekijk hoe het stratenplan van Amsterdam zich heeft ontwikkeld, of hoe de posters van Paradiso door de laatste 50 jaar zijn veranderd. Kom gerust langs in de Centrale OBA om de ontwikkelingen te volgen.
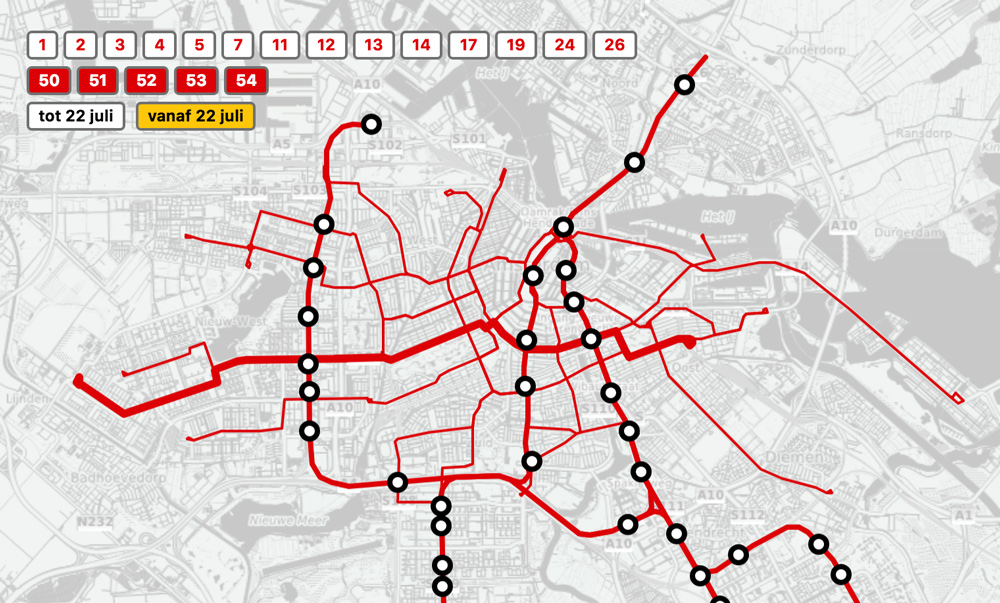
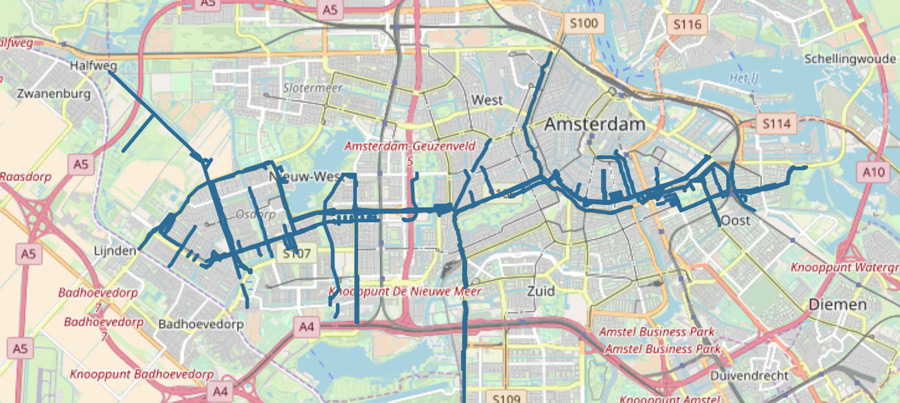
Deze zomer gaat de Noord/Zuidlijn rijden, en op die dag verdwijnen een aantal tramlijnen en gaan een aantal andere lijnen een andere route rijden. De oude en nieuwe lijnen staan op ons Metro & Tram Amsterdam overzicht, met veel historische foto’s uit Amsterdamse collecties.
Als je je door het bovenstaande intro heen hebt geworsteld om meer over de achterliggende SPARQL-queries te lezen, dan kan je nu al opgelucht ademhalen.
Er zijn geen collecties die harde links naar tram- of metrolijnen opgenomen hebben. We hebben tekstueel gezocht in de beschrijving van de objecten:
De reguliere expressie was nodig om bij lijn 1 niet ook bijvoorbeeld lijn 13 terug te krijgen. Oh, en dat ?cho staat voor Cultural Heritage Object.
Helemaal goed gaat dit niet altijd, want Tramlijn 15 is al in 1937 opgeheven en sinds 1965 rijdt er een buslijn met dat nummer. Maar we zouden te veel afbeeldingen missen als we op tramlijn 6[^0-9] hadden gezocht. De metrostations zijn hier en daar wel hard gekoppeld aan collectie afbeeldingen:
Nu de lijnen erin zitten kan je zelf ook andere queries maken – deze ‘gewoon-omdat-het-kan-query’ vraagt bijvoorbeeld naar alle straten die tramlijn 1 na 22 juli kruist en dat levert het volgende plaatje op:
De code van de Metro & Tram Amsterdam sample app staat op GitHub.
Tijdens de Hack-a-LOD hebben we twee nieuwe lab-toepassingen ontwikkeld om te laten zien hoe de AdamLink data kan worden gebruikt.
Menno werkte samen met Bert Spaan aan een betere ontsluiting van kaarten in de beeldbank van het Stadsarchief. Daarvoor rekenden ze de omtrek uit van elke kaart en sloegen deze op als LOD in onze Triple Store. Hierdoor is het nu mogelijk een SPARQL-query te stellen met als resultaat de kaarten die betrekking hebben op het gevraagde punt op de kaart. Dit wordt heel mooi gedemonstreerd in de tool “MapMe!” van Menno (op github). Het initiatief werd op Twitter met veel enthousiasme ontvangen. Richard Zijdeman postte een filmpje op Twitter om de werking uit te leggen en onder aandacht te brengen bij een internationaal publiek. Op de website van Bert staat Amsterdam op de Kaart, waarbij onderscheid gemaakt is tussen de tijden (op github).
Petra en Ivo werkten aan het weergeven van familierelaties tussen personen om daarnaast de beschikbare portretten van deze personen te laten zien. Dit is mogelijk dankzij de koppeling tussen de portretten en Wikidata, zoals Menno eerder beschreef. We hebben de toepassing beperkt tot de leden van twee Amsterdamse families – Backer en Bicker – die een rol spelen in het jongste boek van Gabri van Tussenbroek. Naast de beschikbare portretten in de collecties van het Amsterdam Museum en het Stadsarchief, hebben we ook de collectie van het Rijksmuseum aangesloten. Dat had echter wel als consequentie dat de query erg lang duurt (ca. 8 seconden). Het is Petra gelukt in korte tijd een webinterface te maken, die ze op de lab-website heeft gezet (op github).
Menno en Bert gooiden hoge ogen bij de publieksprijs: ze werden gedeeld derde.